도메인을 중심으로 SW 설계
1. 우리가 필요한 이유
- 도메인을 명확하게 구분하고 객체 간 관계를 올바르게 설계하기 위해
- JPA를 효과적으로 활용하기 위해
- 기술 부채를 줄이기 위한 선행 작업
- DDD에서 필요한 개념을 익히고, 프로젝트에 적용할 수 있는 최소한의 기준을 마련하기 위해
목차
- DDD의 바운디으 컨텍스트 이해
- DDD의 애그리거르(루트 이해)
- 도메인 관점으로 설계

그 결과, 같은 객체간 연관관계가 맺어진다면 도메인관 유지보수 뿐만 아니라 확장성이 쉽지 않게 된다.

종속적인 관계 - 영속성 전이(Cascade)가 가능
생명주기가 같으면 종속적인 관계

독립적인 관계는 서로 간의 영향을 주지 않아야 한다.
생명주기가 다르면 독릭접인 관계
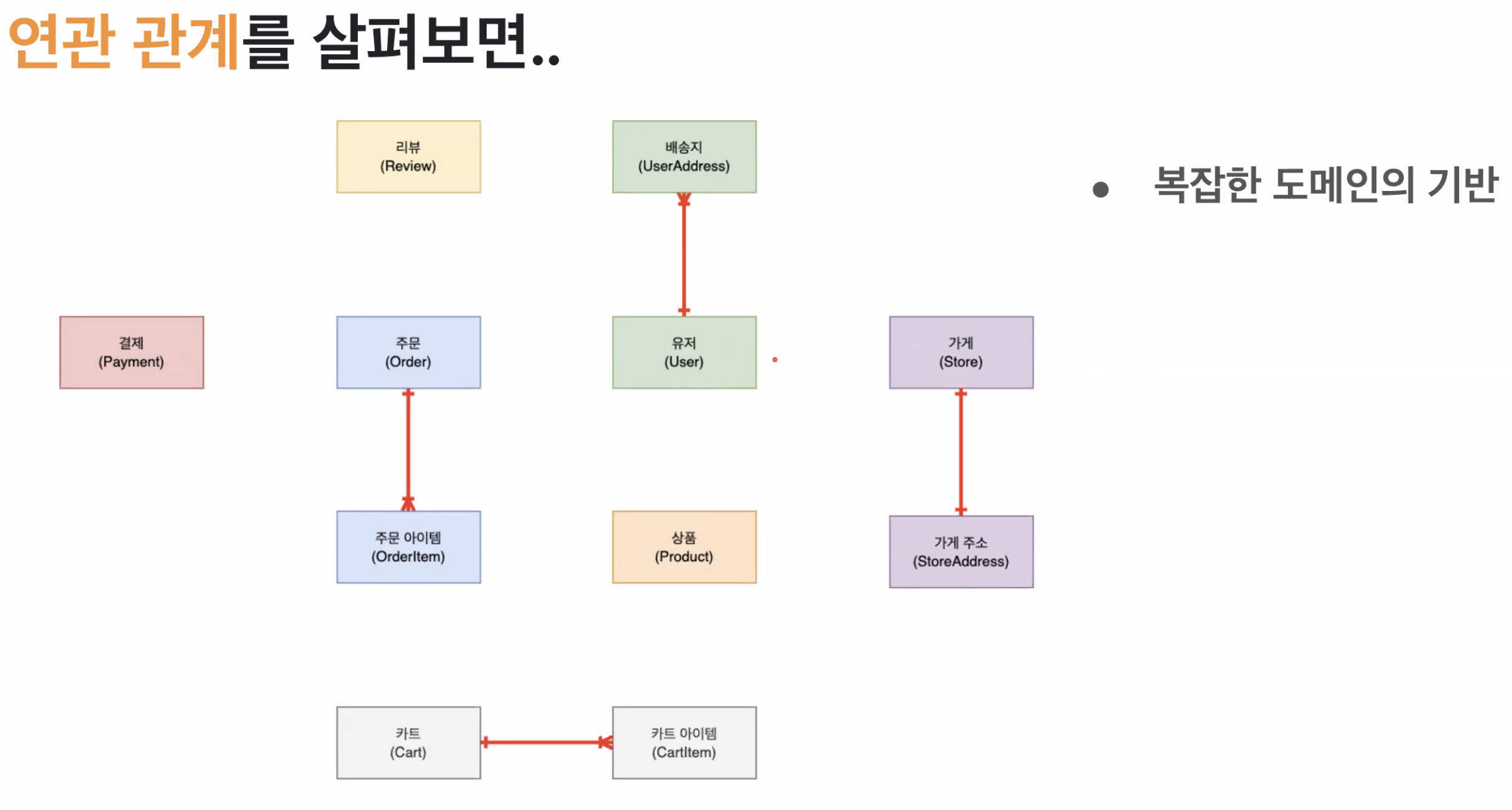
우리의 도메인이 확장되어 복잡하다면...?
복잡하다면 보통 계층적인 구조를 가지고 시작한다.
2. DDD의 핵심 개념
2.1 바운디드 컨텍스트 (Bounded Context)
- 큰 시스템을 여러 개의 작은 컨텍스트로 나누어 독립적으로 설계하고 구현하는 개념
- 각 컨텍스트는 특정 비즈니스 문제 영역을 나타내며, 내부적으로 일관된 용어, 개념, 규칙을 유지
- 컨텍스트 간에는 **인터페이스(REST API, Event 등)**를 통해 상호작용
- 컨텍스트를 독립적으로 설계하면 복잡성이 줄고, 유연성이 높아짐
- 실무에서는 보통 4계층 구조를 따른다:
- presentation (Controller)
- application (Service, Facade)
- domain (Entity, Repository)
- infrastructure (Concrete Class)
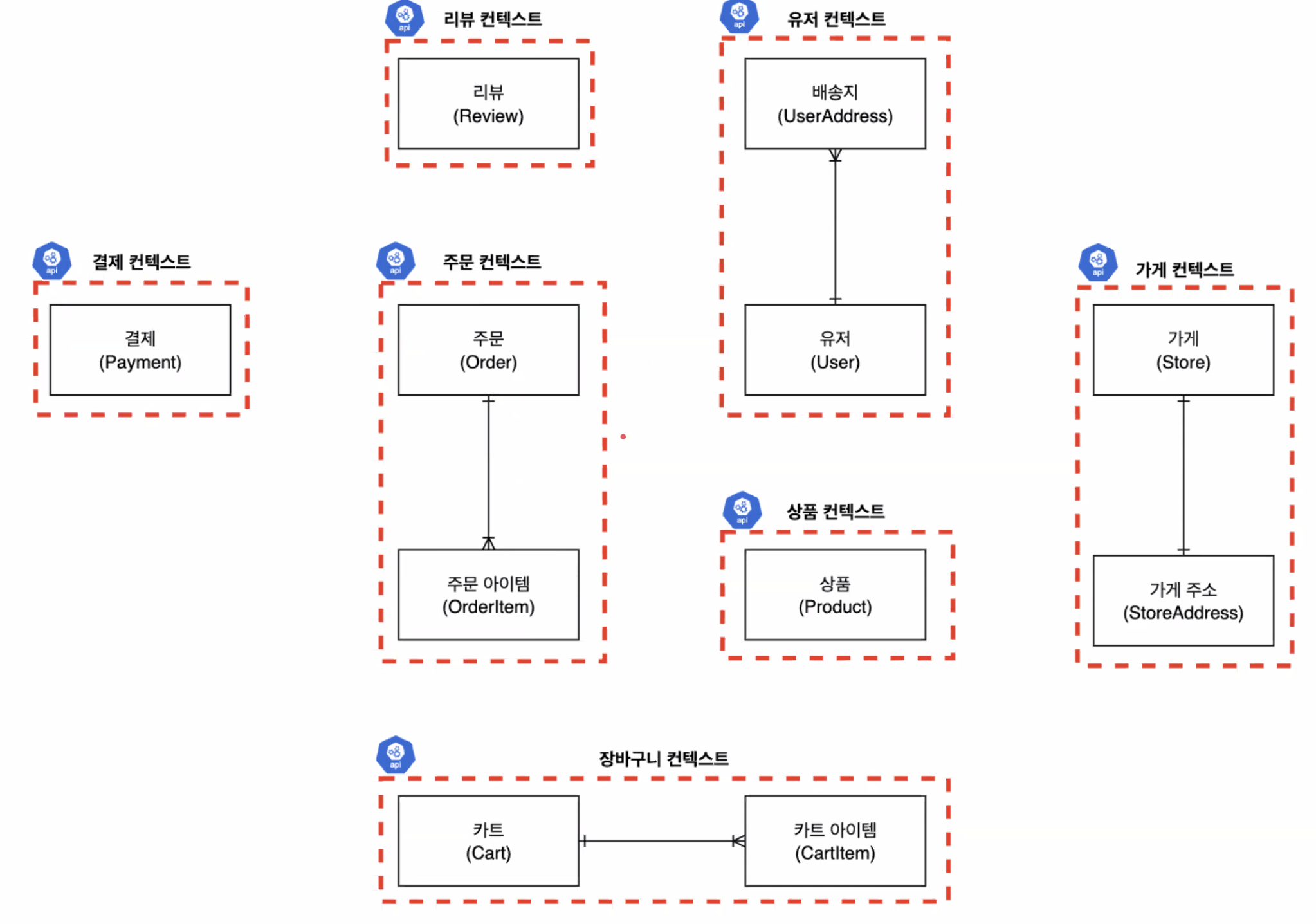
2.2 애그리거트(Aggregate)와 애그리거트 루트 (Aggregate Root)
- 애그리거트: 논리적으로 하나의 단위로 묶여야 하는 객체들의 집합
- 애그리거트 루트: 애그리거트 내부에서 유일한 진입점(Entry Point) 역할을 하는 객체
- 애그리거트 루트는:
- 데이터의 일관성을 유지 → 객체 간 관계를 무질서하게 만드는 것을 방지
- 변경 범위(트랜잭션)를 제어 → 변경할 데이터 범위를 제한하여 성능과 안정성을 높임
- 도메인 모델을 명확하게 구분 → 도메인 경계를 정의하고 유지보수성을 향상
- 엔티티 간 직접 참조 방지 → 결합도를 낮추고 무분별한 관계 형성을 막음
- 데이터 저장소와의 관계 정리 → 애그리거트 단위로 저장하고 조회하여 무결성을 보장
규칙
- 애그리거트 루트 외부에서 내부 객체를 직접 수정할 수 없음
- 애그리거트는 영속성 컨텍스트 내부에서 함께 관리되어야 함
- 데이터 저장소(Repository)는 애그리거트 루트를 통해서만 저장/조회해야 함

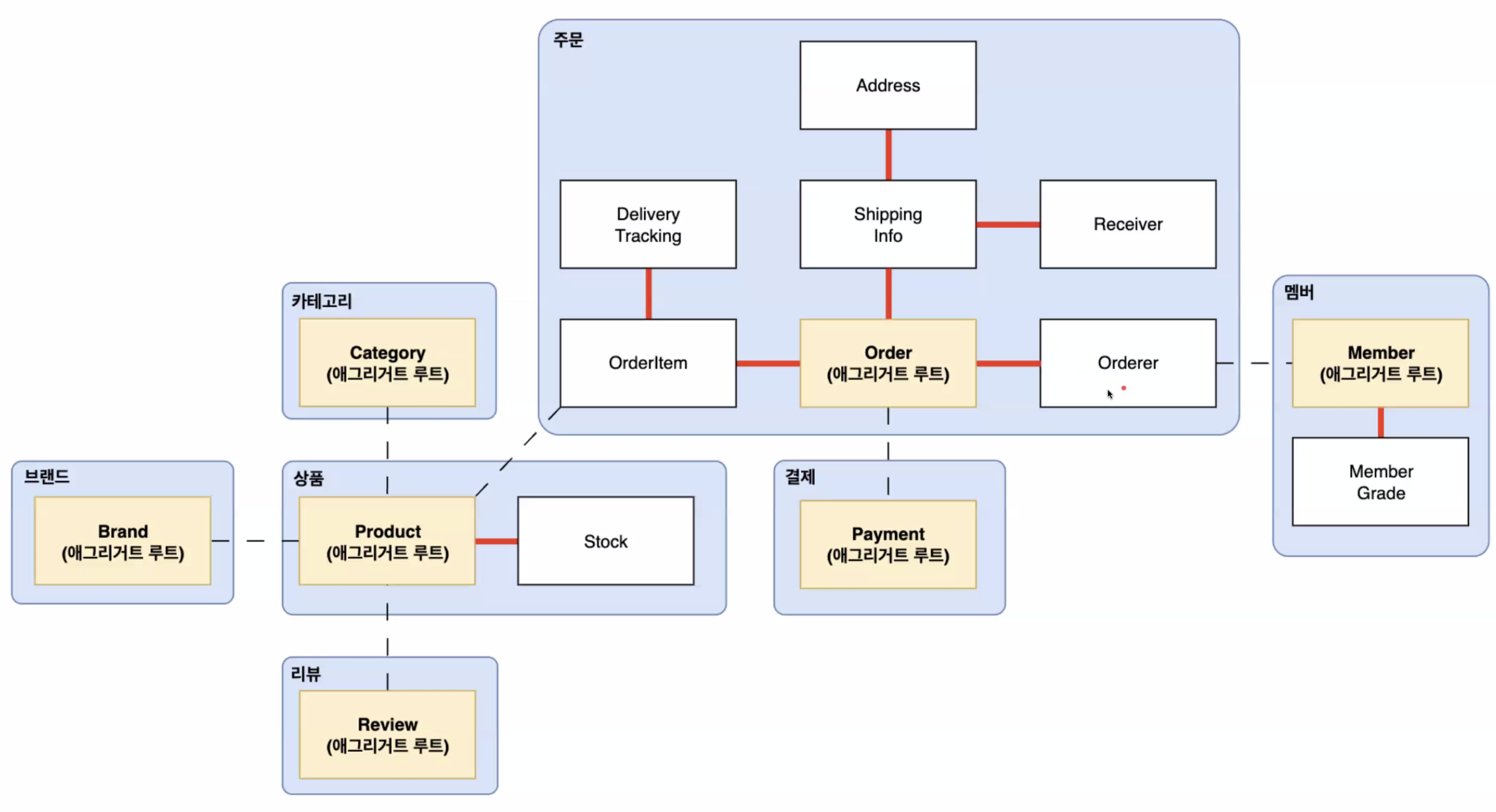
3. 도메인 관점에서의 설계 접근법
3.1 관계형 DB와 객체 설계의 차이
- RDB에서는 **FK(외래키)**로 연관관계를 맺음 → 조인을 통해 데이터를 가져옴
- 하지만 객체 관점에서는 FK가 아닌 객체 간 연관관계를 고민해야 함
- ORM을 사용하면 RDBMS <-> ORM <-> Application 형태로 관계를 정의할 수 있음
- 연관 관계 설정 시 고려할 점
- 생명 주기가 같으면 종속적 관계 → Cascade 설정 가능
- 생명 주기가 다르면 독립적 관계 → 서로 영향을 주지 않도록 설계
보통 계층적인 구조를 가지고 시작하는 것이 좋음
4. 모놀리식 → MSA 전환
- 도메인 간 직접 의존성을 줄이는 방법
- 다른 도메인 호출 시 공통 모듈로 예를 들어, 웹 클라이언트(REST API, Event 등)를 활용
- 모놀리식에서는 Service 또는 Facade를 통해 도메인 간 호출로 보통하게 된다.
- 모놀리식에서 MSA로 전환하는 구조
- MSA에서는 도메인 간 독립성을 유지하고, REST API, Event, Client SDK 등을 활용하여 통신
5. 도메인 설계 프로세스 필요성
- 도메인 도출: 필요한 도메인을 먼저 정의 (예: 사용자, 가게, 상품, 주문, 결제)
- 대표 도메인과 하위 도메인 분류 (애그리거트 정의)
- 구현 모델(Class) 설계
- 개념 모델을 실제 코드 모델로 변환
- 하위 도메인 간 연관 관계 정의
- 바운디드 컨텍스트 설정
- 모놀리식에서는 패키지 분리, MSA에서는 물리적 분리

6. DDD가 실무에서 잘 사용되지 않는 이유
- 트랜잭션 스크립트 패턴이 더 실용적인 경우:
- 단순한 CRUD 기반 프로젝트
- 빠르게 MVP(최소 기능 제품)를 만들어야 하는 경우
- DDD 적용 경험이 부족한 경우
결론
도메인의 복잡도에 따라 도메인 모델 패턴 vs 트랜잭션 스크립트 패턴 중 적절한 방법을 선택해야 함.
도메인 간 의존성과 공통 모듈의 관계
- 질문: 도메인 간 의존을 하지 않으면 공통 모듈에 의존하게 되는 건가요?
- 답변: 공통 모듈에 의존하는 것이 아니라, 웹 클라이언트가 도메인 간 호출을 대신하는 구조라고 보면 된다.
- 모놀리식 구조에서는 Service 또는 Facade를 통해 도메인 간 호출이 이루어짐
- MSA 구조에서는 도메인 간 직접 호출을 피하고, REST API, Event, Client SDK 등을 활용하여 통신
- 즉, 공통 모듈을 공유하는 것이 아니라, 독립적으로 호출하는 방식을 선택하는 것이 더 적절함
애그리거트(Aggregate)와 컨텍스트(Context)의 차이
- 질문: 애그리거트와 컨텍스트의 개념이 헷갈리는데, 비슷한 개념이라고 생각하면 될까?
- 답변: 비슷하지만 다름. 컨텍스트(Bounded Context)는 상위 개념, 애그리거트(Aggregate)는 하위 개념이다.
- 컨텍스트(Bounded Context)
- 도메인의 경계를 나타내며, 독립적으로 동작하는 단위 (예: 주문 컨텍스트, 상품 컨텍스트, 리뷰 컨텍스트)
- 하나의 컨텍스트 내부에서는 일관된 비즈니스 로직과 용어를 유지해야 함
- 애그리거트(Aggregate)
- 컨텍스트 내에서 특정 도메인 로직을 수행하는 연관된 객체들의 집합
- 애그리거트는 단일 트랜잭션 단위로 관리됨
- 한 컨텍스트 안에는 **여러 개의 애그리거트 루트(Aggregate Root)**가 존재할 수 있음
- 컨텍스트(Bounded Context)
예시
- 주문 컨텍스트(Bounded Context)
- 주문 애그리거트(Aggregate) → 주문(Order) + 주문 항목(OrderItem)
- 결제 애그리거트(Aggregate) → 결제(Payment) + 결제 내역(PaymentDetail)
- 상품 컨텍스트(Bounded Context)
- 상품 애그리거트(Aggregate) → 상품(Product) + 카테고리(Category)
7. 최종 정리
- 바운디드 컨텍스트: 도메인 간 경계를 명확히 구분 (예: 주문, 상품, 리뷰 컨텍스트)
- 애그리거트: 논리적으로 연관된 모델들의 그룹
- 애그리거트 루트: 애그리거트 내에서 유일한 진입 지점
- 도메인 관점 설계: 개념 모델 → 구현 모델 변환, 도메인별 연관관계 설정, 바운디드 컨텍스트 설계
복잡한 도메인에서 필요하다 하셨다. 그러면 복잡한 기준이 뭘까요?
복잡한 도메인에서 DDD가 필요한 이유: ‘복잡함’의 기준은?
Q: 복잡한 도메인에서 DDD가 필요하다고 했는데, ‘복잡한’ 기준이 뭘까요?
A: 정확한 수치나 공식적인 기준이 있는 것은 아니지만, 다음과 같은 요소가 있으면 복잡한 도메인이라고 볼 수 있어요.
1. 비즈니스 로직이 많고 변경이 잦은 경우
- 단순 CRUD가 아니라, 비즈니스 규칙을 적용하는 로직이 많을 때
- 예: "A 상품을 구매하면 B 쿠폰을 지급하고, 특정 기간에는 C 조건이 추가됨"
- 서비스 도메인이 커질수록 규칙 간 충돌이나 변경에 대한 영향도가 커지는 문제 발생
2. 도메인 간의 연관 관계가 복잡한 경우
- 단순히 테이블 간 조인이 아니라, 도메인 간 협업이 필요할 때
- 예: 주문(Order) → 결제(Payment) → 배송(Delivery) 과정에서 여러 도메인이 서로 영향을 주는 경우
- 변경이 잦으면 강한 결합(높은 의존성)이 문제가 됨
- FK 기반의 단순한 관계가 아니라, 도메인 이벤트, 트랜잭션 분리 등이 필요한 경우
3. 트랜잭션이 여러 도메인을 걸쳐 있는 경우
- 하나의 트랜잭션에서 여러 개의 도메인이 변경되어야 하는 경우
- 예: 주문을 생성하면 결제도 함께 진행되어야 하고, 재고도 감소해야 하는 경우
- 트랜잭션을 무조건 한 번에 끝내려고 하면 성능 저하 & 확장성 문제가 발생할 수 있음
- CQRS, 이벤트 소싱 같은 기법이 필요할 수도 있음
4. 시스템이 커지고, 여러 팀이 협업하는 경우
- 작은 프로젝트에서는 단순한 Service Layer 패턴이 충분하지만,
- 서비스가 커지면 도메인 경계를 나누는 것이 중요
- 여러 팀이 각각의 도메인을 관리해야 할 때, 일관된 개념과 모델이 필요함
Elasticsearch는 분산형 검색 및 분석 엔진으로, 대량의 데이터를 빠르게 검색하고 분석할 수 있도록 설계된 오픈소스 소프트웨어야.
Apache Lucene 기반으로 만들어졌으며, JSON 문서를 저장하고 검색하는 방식을 사용해.
Elasticsearch의 주요 특징
🔹 1. 실시간 검색 및 분석
- 데이터를 저장하면 즉시(near real-time) 검색 가능
- 로그 분석, 데이터 시각화, 추천 시스템 등에 활용됨
🔹 2. 분산형 아키텍처
- 여러 개의 노드(서버)로 구성된 클러스터 형태
- 데이터가 자동으로 샤딩(Sharding) 및 복제(Replication)되므로 확장성이 뛰어남
🔹 3. JSON 기반 문서 저장
- NoSQL 데이터베이스처럼 JSON 형식으로 데이터를 저장
- RDB의 테이블과 비슷한 인덱스(Index) 개념 사용
🔹 4. RESTful API 지원
- HTTP를 통해 데이터를 검색하고 조작 가능
- GET, POST, PUT, DELETE 메서드를 활용한 CRUD 작업
🔹 5. 강력한 풀텍스트 검색 (Full-Text Search)
- 형태소 분석(Tokenizer) 및 필터(Analyzer) 적용 가능
- 특정 키워드뿐만 아니라 유사한 단어까지 검색 가능
Elasticsearch의 핵심 개념
개념설명
| Index | RDBMS의 데이터베이스 개념 |
| Document | RDBMS의 Row(레코드)와 유사한 JSON 데이터 단위 |
| Shard | 인덱스를 나누어 저장하는 수평 분할 단위 |
| Replica | 샤드 복사본으로, 장애 대응 및 부하 분산 역할 |
| Query DSL | SQL 대신 JSON 형식으로 데이터를 검색하는 쿼리 언어 |
Elasticsearch 사용 예시
✅ 문서 색인(Indexing)
json
복사편집
PUT my_index/_doc/1 { "title": "Elasticsearch 소개", "content": "Elasticsearch는 검색 및 분석을 위한 강력한 엔진입니다." }
✅ 문서 검색(Search)
json
복사편집
GET my_index/_search { "query": { "match": { "content": "검색" } } }
Elasticsearch의 활용 사례
🔹 로그 및 모니터링 시스템 → ELK(Stack) 구성 (Elasticsearch + Logstash + Kibana)
🔹 검색 엔진 → 전자상거래, 블로그, 문서 검색 최적화
🔹 데이터 분석 → 대량의 데이터를 빠르게 분석 및 시각화
정리
- Elasticsearch는 빠른 검색과 분석을 위한 분산형 검색 엔진
- JSON 문서를 저장하고 검색하는 방식
- RESTful API를 지원하여 쉽게 사용 가능
- 대량의 데이터 검색/분석, 로그 모니터링, 추천 시스템 등에 활용됨
'Sparta(JAVA심화3기) - TIL > Chap.02' 카테고리의 다른 글
| CHAP.02 : MSA Project Day03 - SCRUM (0) | 2025.03.15 |
|---|---|
| CHAP.02 : MSA Project Day02 - SCRUM (0) | 2025.03.12 |
| CH.2 대규모 AI 시스템 설계 프로젝트 S.A 제출 (0) | 2025.03.12 |
| CHAP.02 : MSA Project Day01 - SCRUM (0) | 2025.03.11 |
| CHAP02. MSA설계 - 프로젝트 팀 편성 (0) | 2025.03.10 |